为什么要使用web缓存?
Web缓存存在于服务器和客户端之间。Web缓存密切注视着服务器-客户端之间的通信,监控请求,并且把请求输出的内容(例如html页面、 图片和文件)另存一份;然后,如果下一个请求是相同的URL,则直接使用保存的副本,而不是再次请求源服务器。
使用Web缓存的好处是显而易见的:
- 减少网络延迟,加快页面打开速度--缓存比源服务器离客户端更近,因此,从缓存请求内容比从源服务器所用时间更少,缓存的使用能够明显加快页面打开速度,达到更好的体验。
- 降低服务器的压力--给网络资源设定有效期之后,用户可以重复使用本地的缓存,减少对源服务器的请求,间接降低服务器的压力。同时,搜索引擎的爬虫机器人也能根据过期机制降低爬取的频率,也能有效降低服务器的压力。
- 减少网络带宽损耗--无论对于网站运营者或者用户,带宽都代表着金钱,当Web缓存副本被使用时,只会产生极小的网络流量,可以有效的降低运营成本。
现在的大型网站,随便一个页面都是一两百个请求,每天 pv 都是亿级别,如果没有缓存,用户体验会急剧下降、同时服务器压力和网络带宽都面临严重的考验。 缓存和重用以前获取的资源的是优化网页性能很重要的一个方面。
缺点也是有的:
- 缓存没有清理机制--这些缓存的文件会永久性地保存在机器上,在特定的时间内,这些文件可能是帮了你大忙,但是时间一长,我们已经不再需要浏览之前的这些网页,这些文件就成了无效或者无用的文件,它们存储在用户硬盘中只会占用空间而没有任何用处,如果要缓存的东西非常多,那就会撑暴整个硬盘空间。
- 给开发带来的困扰--明明修改了样式文件、图片、视频或脚本,刷新页面或部署到站点之后看不到修改之后的效果。
所以在产品开发的时候我们总是想办法避免缓存产生,而在产品发布之时又在想策略管理缓存提升网页的访问速度。了解浏览器的缓存命中原理和清除方法,对我们大有裨益。
缓存的分类
在Web应用领域,Web缓存大致可以分为以下几种类型:
1.数据库数据缓存
Web应用,特别是社交网络服务类型的应用,往往关系比较复杂,数据库表繁多,如果频繁进行数据库查询,很容易导致数据库不堪重荷。为了提供查询的性能,会将查询后的数据放到内存中进行缓存,下次查询时,直接从内存缓存直接返回,提供响应效率。比如常用的缓存方案有memcached,redis等。
2.服务器端缓存
代理服务器缓存
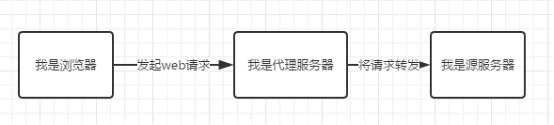
代理服务器是浏览器和源服务器之间的中间服务器,浏览器先向这个中间服务器发起Web请求,经过处理后(比如权限验证,缓存匹配等),再将请求转发到源服务器。代理服务器缓存的运作原理跟浏览器的运作原理差不多,只是规模更大。可以把它理解为一个共享缓存,不只为一个用户服务,一般为大量用户提供服务,因此在减少相应时间和带宽使用方面很有效,同一个副本会被重用多次。常见代理服务器缓存解决方案有Squid,Nginx,Apache等。
CDN缓存
CDN(Content delivery networks)缓存,也叫网关缓存、反向代理缓存。CDN缓存一般是由网站管理员自己部署,为了让他们的网站更容易扩展并获得更好的性能。浏览器先向CDN网关发起Web请求,网关服务器后面对应着一台或多台负载均衡源服务器,会根据它们的负载请求,动态将请求转发到合适的源服务器上。虽然这种架构负载均衡源服务器之间的缓存没法共享,但却拥有更好的处扩展性。从浏览器角度来看,整个CDN就是一个源服务器,浏览器和服务器之间的缓存机制,在这种架构下同样适用。
3.浏览器端缓存
浏览器缓存根据一套与服务器约定的规则进行工作,在同一个会话过程中会检查一次并确定缓存的副本足够新。如果你浏览过程中,比如前进或后退,访问到同一个图片,这些图片可以从浏览器缓存中调出而即时显现。
4.Web应用层缓存
应用层缓存指的是从代码层面上,通过代码逻辑和缓存策略,实现对数据,页面,图片等资源的缓存,可以根据实际情况选择将数据存在文件系统或者内存中,减少数据库查询或者读写瓶颈,提高响应效率。
缓存如何发挥作用
请看下面的图:


缓存控制设置字段和原理
1.HTML Meta标签控制缓存
浏览器缓存机制,其实主要就是HTTP协议定义的缓存机制(如: Expires; Cache-control等)。但是也有非HTTP协议定义的缓存机制,如使用HTML Meta 标签,Web开发者可以在HTML页面的<head>节点中加入<meta>标签,代码如下:
<META HTTP-EQUIV="Pragma" CONTENT="no-cache"> <META HTTP-EQUIV="Expires" CONTENT="0">
上述代码的作用是告诉浏览器当前页面不被缓存,每次访问都需要去服务器拉取。使用上很简单,但只有部分浏览器可以支持,
事实上这种禁用缓存的形式用处很有限:
1. 仅有IE才能识别这段meta标签含义,其它主流浏览器仅能识别“Cache-Control: no-store”的meta标签。
2. 在IE中识别到该meta标签含义,并不一定会在请求字段加上Pragma,但的确会让当前页面每次都发新请求(仅限页面,页面上的资源则不受影响)。
而且所有缓存代理服务器都不支持,因为代理不解析HTML内容本身。而广泛应用的还是 HTTP头信息来控制缓存,下面我主要介绍HTTP协议定义的缓存机制
2.HTTP头信息控制缓存
我们先来瞅一眼http1.1协议报文首部字段中与缓存相关的字段
1.通用首部字段

2.请求首部字段

3.响应首部字段

4.实体首部字段

http1.0 时代缓存字段详解
在 http1.0 时代,给客户端设定缓存方式可通过两个字段Pragma和Expires来规范。虽然这两个字段早可抛弃,但http协议做了向下兼容,所以依然可以看到。
1.Pragma
Pragma:设置页面是否缓存,为Pragma则缓存,no-cache则不缓存
当该字段值为no-cache的时候,会知会客户端不要对该资源读缓存,即每次都得向服务器发一次请求才行。
2.Expires
有了Pragma来禁用缓存,自然也需要有个东西来启用缓存和定义缓存时间,对http1.0而言,Expires就是做这件事的首部字段。 Expires的值对应一个GMT(格林尼治时间),比如Mon, 22 Jul 2002 11:12:01 GMT来告诉浏览器资源缓存过期时间,如果还没过该时间点则不发请求。
如果Pragma头部和Expires头部同时存在,则起作用的会是Pragma,需要注意的是,响应报文中Expires所定义的缓存时间是相对服务器上的时间而言的,其定义的是资源“失效时刻”,如果客户端上的时间跟服务器上的时间不一致(特别是用户修改了自己电脑的系统时间),那缓存时间可能就没啥意义了。
http1.1时代缓存字段详解
1.Cache-Control
针对上述的“Expires时间是相对服务器而言,无法保证和客户端时间统一”的问题,http1.1新增了 Cache-Control 来定义缓存过期时间。注意:若报文中同时出现了 Expires 和 Cache-Control,则以 Cache-Control 为准。
也就是说优先级从高到低分别是 Pragma -> Cache-Control -> Expires 。
Cache-Control也是一个通用首部字段,这意味着它能分别在请求报文和响应报文中使用。在RFC中规范了 Cache-Control 的格式为:
<span class="hljs-string">"Cache-Control" <span class="hljs-string">":" cache-directive</span></span>
作为请求首部时,cache-directive 的可选值有:
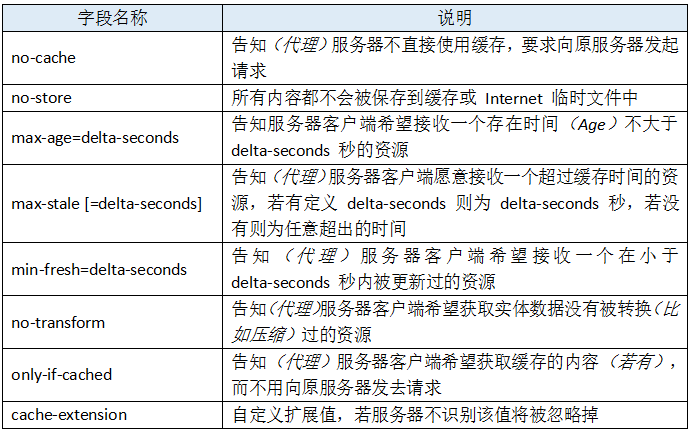
Cache-Control: no-cache:这个很容易让人产生误解,使人误以为是响应不被缓存。实际上Cache-Control: no-cache是会被缓存的,
只不过每次在向客户端(浏览器)提供响应数据时,缓存都要向服务器评估缓存响应的有效性。
Cache-Control: no-store:这个才是响应不被缓存的意思。
作为响应首部时,cache-directive 的可选值有:
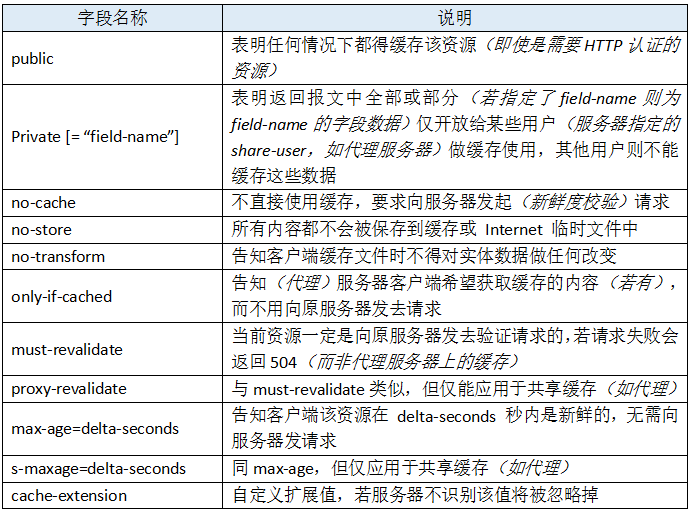
Cache-Control 允许自由组合可选值,例如:
<span class="hljs-keyword">Cache-Control: <span class="hljs-keyword">max-age=<span class="hljs-number">3600, must-revalidate</span></span></span>
它意味着该资源是从原服务器上取得的,且其缓存(新鲜度)的有效时间为一小时,在后续一小时内,用户重新访问该资源则无须发送请求。
当然这种组合的方式也会有些限制,比如 no-cache 就不能和 max-age、min-fresh、max-stale 一起搭配使用。
2.Last-Modified/If-Modified-Since
Last-Modified/If-Modified-Since要配合Cache-Control使用。
(1) Last-Modified:标示这个响应资源的最后修改时间。web服务器在响应请求时,告诉浏览器资源的最后修改时间。
(2) If-Modified-Since:当资源过期时(使用Cache-Control标识的max-age),发现资源具有Last-Modified声明,则再次向web服务器请求时带上头 If-Modified-Since,表示请求时间。web服务器收到请求后发现有头If-Modified-Since 则与被请求资源的最后修改时间进行比对。若最后修改时间较新,说明资源又被改动过,则响应整片资源内容(写在响应消息包体内),HTTP 200;若最后修改时间较旧,说明资源无新修改,则响应HTTP 304 (无需包体,节省浏览),告知浏览器继续使用所保存的cache。
3.Etag/If-None-Match
Etag/If-None-Match也要配合Cache-Control使用。
(1) Etag:web服务器响应请求时,告诉浏览器当前资源在服务器的唯一标识(生成规则由服务器觉得)。Apache中,ETag的值,默认是对文件的索引节(INode),大小(Size)和最后修改时间(MTime)进行Hash后得到的。
(2)If-None-Match:当资源过期时(使用Cache-Control标识的max-age),发现资源具有Etage声明,则再次向web服务器请求时带上头If-None-Match (Etag的值)。web服务器收到请求后发现有头If-None-Match 则与被请求资源的相应校验串进行比对,决定返回200或304。
4.既生Last-Modified何生Etag?
你可能会觉得使用Last-Modified已经足以让浏览器知道本地的缓存副本是否足够新,为什么还需要Etag(实体标识)呢?HTTP1.1中Etag的出现主要是为了解决几个Last-Modified比较难解决的问题:
(1) Last-Modified标注的最后修改只能精确到秒级,如果某些文件在1秒钟以内,被修改多次的话,它将不能准确标注文件的修改时间
(2)如果某些文件会被定期生成,当有时内容并没有任何变化,但Last-Modified却改变了,导致文件没法使用缓存
(3)有可能存在服务器没有准确获取文件修改时间,或者与代理服务器时间不一致等情形
Etag是服务器自动生成或者由开发者生成的对应资源在服务器端的唯一标识符,能够更加准确的控制缓存。Last-Modified与ETag是可以一起使用的,服务器会优先验证ETag,一致的情况下,才会继续比对Last-Modified,最后才决定是否返回304。
5.不太常用的两个http字段If-Unmodified-Since/If-Match
(1)If-Unmodified-Since: Last-Modified-value
告诉服务器,若Last-Modified没有匹配上(资源在服务端的最后更新时间改变了),则应当返回412(Precondition Failed) 状态码给客户端。
当遇到下面情况时,If-Unmodified-Since 字段会被忽略:
1. Last-Modified值对上了(资源在服务端没有新的修改); 2. 服务端需返回2XX和412之外的状态码; 3. 传来的指定日期不合法
(2)If-Match: ETag-value
告诉服务器如果没有匹配到ETag,或者收到了“*”值而当前并没有该资源实体,则应当返回412(Precondition Failed) 状态码给客户端。否则服务器直接忽略该字段。
浏览器缓存流程图
小结一下,浏览器第一次请求

浏览器第二次请求

如何配置
1)通过代码的方式,在web服务器返回的响应中添加Expires和Cache-Control Header;
比如在JavaWeb里面,我们可以使用类似下面的代码设置强缓存:
java.util.Date date = new java.util.Date();
response.setDateHeader("Expires",date.getTime()+20000); //Expires:过时期限值
response.setHeader("Cache-Control", "public"); //Cache-Control来控制页面的缓存与否,public:浏览器和缓存服务器都可以缓存页面信息;
response.setHeader("Pragma", "Pragma"); //Pragma:设置页面是否缓存,为Pragma则缓存,no-cache则不缓存还可以通过类似下面的java代码设置不启用强缓存:
response.setHeader( "Pragma", "no-cache" );
response.setDateHeader("Expires", 0);
response.addHeader( "Cache-Control", "no-cache" );//浏览器和缓存服务器都不应该缓存页面信息2)通过配置web服务器的方式,让web服务器在响应资源的时候统一添加Expires和Cache-Control Header。
tomcat提供了一个ExpiresFilter专门用来配置强缓存

nginx和apache作为专业的web服务器,都有专门的配置文件,可以配置expires和cache-control,
Nginx服务器的配置方法为:
location ~ .*\.(gif|jpg|jpeg|png|bmp|swf)$ {
#过期时间为30天,#图片文件不怎么更新,过期可以设大一点,
expires 30d;
}
location ~ .*\.(js|css)$ {
#如果频繁更新,则可以设置得小一点。
expires 1d;
add_header Cache-Control max-age=86400;
etag on;
}Apache服务器的配置方法为:
<Location ~ "\.(js|css|png|jpg|gif|bmp|html)$">
ExpiresActive On
ExpiresDefault "access plus 1 hours"
Header set Cache-Control max-age=3600
Header unset Pragma
</Location>
<Location ~ "\.(do|jsp|aspx|asp|php|json|action|ashx|axd|cgi)$">
Header set Cache-Control no-cache,no-store,max-age=0
Header unset Expires
Etag INode Mtime Size
</Location>3.缓存配置的一些注意事项
1.只有get请求会被缓存,post请求不会
2.Etag 在资源分布在多台机器上时,对于同一个资源,不同服务器生成的Etag可能不相同,此时就会导致304协议缓存失效,客户端还是直接从server取资源。可以自己修改服务器端etag的生成方式,根据资源内容生成同样的etag。需要注意的是分布式系统里多台机器间文件的last-modified必须保持一致,以免负载均衡到不同机器导致比对失败,Yahoo建议分布式系统尽量关闭掉Etag(每台机器生成的etag都会不一样,因为除了 last-modified、文档节点也很难保持一致)
用户行为与缓存

缓存的清除方法
由于在开发的时候不会专门去配置强缓存,而浏览器又默认会缓存图片,css和js等静态资源,所以开发环境下经常会因为强缓存导致资源没有及时更新而看不到最新的效果,解决这个问题的方法有很多,常用的有以下几种:
1)直接ctrl+f5,这个办法能解决页面直接引用的资源更新的问题;
2)使用ctrl+shift+delete清除缓存;
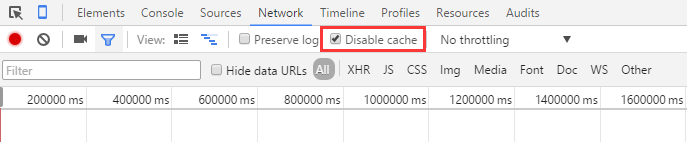
3)如果用的是chrome,可以F12在network那里把缓存给禁掉(这是个非常有效的方法):
4)在开发阶段,给资源加上一个动态的参数,如css/index.css?v=0.0001,由于每次资源的修改都要更新引用的位置,同时修改参数的值,所以操作起来不是很方便,一般使用前端的构建工具来修改这个参数或 在动态页面比如jsp里开发就可以用服务器变量来解决(v=${sysRnd});
1.原生写法
function addVersion(asset){
asset.forEach(function(item,index){
if(item.indexOf('.js') != -1){
document.write('<script src="'+item+'?v='+ (new Date().getTime()) +'"><\/script>');
}else if(item.indexOf('.css') != -1){
document.write('<link rel="stylesheet" href="'+item+'?v='+(new Date().getTime())+'">');
}
});
}2.采用gulp插件
(1)gulp-rev-append

(2)gulp-rev和gulp-rev-collector也能实现同样的功能
// 修改html和css文件,给静态文件打戳
gulp.task('stamp', function(){
gulp.src(['rev/*.json', dest.css + "**/*.css"]).
pipe(revCollector({
replaceReved: true
})).
// 修改为 ?v=stamp 形式
pipe(replace(/\-([0-9a-z]{8,})\.(png|jpg|gif|ico)/g, function(a, b, c){
return '.' + c + '?v=' + b;
})).
pipe(gulp.dest(dest.css));
gulp.src(['rev/*.json', src.html]).
pipe(revCollector({
replaceReved: true
})).
// 修改为 ?v=stamp 形式
pipe(replace(/\-([0-9a-z\-]{8,})\.(css|js)/g, function(a, b, c){
return '.' + c + '?v=' + b;
})).
pipe(gulp.dest(dest.html));
});5)如果资源引用的页面,被嵌入到了一个iframe里面,可以在iframe的区域右键单击重新加载该页面,以chrome为例:

6)如果缓存问题出现在ajax请求中,最有效的解决办法就是ajax的请求地址追加随机数;
7)还有一种情况就是动态设置iframe的src时,有可能也会因为缓存问题,导致看不到最新的效果,这时候在要设置的src后面添加随机数也能解决问题;
8)如果你用的是grunt和gulp这种前端工具开发,通过它们的插件比如grunt-contrib-connect或gulp-connect来启动一个静态服务器,则完全不用担心开发阶段的资源更新问题,因为在这个静态服务器下的所有资源返回的respone header中,cache-control始终被设置为不缓存:

与之相关的--本地存储和离线存储
localStorage/sessionStorage
localStorage.setItem("name", "Robert");
localStorage.getItem("name");这样的存取最多可以存储5M的数据(localStorge在Android webview中不支持扩容,只有在pc浏览器中超限才会弹出扩容提示 ),给你更多选择的空间。但是由于本地存储是基于字符串的存储,存储一串没有结构的字符串并不是一个理想的选择。因此,我们可以利用浏览器中原生的JSON支持来将JavaScript对象转化成字符串,从而保存到本地数据中,在读取的时候也可以将其转换回JavaScript对象。
缓存和使用图片的方法
//在本地存储中保存图片
var storageFiles = JSON.parse(localStorage.getItem("storageFiles")) || {},
elephant = document.getElementById("elephant"),
storageFilesDate = storageFiles.date,
date = new Date(),
todaysDate = (date.getMonth() + 1).toString() + date.getDate().toString();
// 检查数据,如果不存在或者数据过期,则创建一个本地存储
if (typeof storageFilesDate === "undefined" || storageFilesDate < todaysDate) {
// 图片加载完成后执行
elephant.addEventListener("load", function () {
var imgCanvas = document.createElement("canvas"),
imgContext = imgCanvas.getContext("2d");
// 确保canvas尺寸和图片一致
imgCanvas.width = elephant.width;
imgCanvas.height = elephant.height;
// 在canvas中绘制图片
imgContext.drawImage(elephant, 0, 0, elephant.width, elephant.height);
// 将图片保存为Data URI
storageFiles.elephant = imgCanvas.toDataURL("image/png");
storageFiles.date = todaysDate;
// 将JSON保存到本地存储中
try {
localStorage.setItem("storageFiles", JSON.stringify(storageFiles));
}
catch (e) {
console.log("Storage failed: " + e);
}
}, false);
// 设置图片
elephant.setAttribute("src", "elephant.png");
}
else {
// Use image from localStorage
elephant.setAttribute("src", storageFiles.elephant);
}sessionStorage的数据只存储到特定的会话中,不属于持久化的存储,所以关闭浏览器会清除数据。和localstorage具有相同的方法。
离线存储
设置方法
1. 在HTML5的html标签中添加一个 manifest="XXX.appcache" 属性声明
<!DOCTYPE html> <html manifest="list.appcache">
2.XXX.appcache文件中定义需要缓存的文件清单(里面的资源文件的路径是相对于manifest的路径而言的)
CACHE MANIFEST # VERSION 0.3 # 直接缓存的文件 CACHE: # 需要在线访问的文件 NETWORK: # 替代方案 FALLBACK:
CACHE MANIFEST --(必须) 此标题下列出的文件将在首次下载后进行缓存
#V1.0.2../addDevice.html ../static/css/reset.css ../static/js/addDevice.js ../static/img/ms1.png ../static/img/clean-face.jpg
NETWORK----(可选)
(1)通配符'*'表示不在CACHE MANIFEST清单里的文件,每次都要重新请求
*
(2)或者指定特定文件,比如login.asp不被离线存储,每次都要重新发起请求
login.asp
FALLBACK----(可选) 断网时访问指定路径时的替换文件
如断网时访问/html5/ 目录下的所有资源文件,则用 "offline.html" 替代
/html5/ /offline.html
更新原理
更新了manifest文件,浏览器会自动的重新下载新的manifest文件并把manifest缓存列表中的所有文件重新请求一次(第二次刷新替换本地缓存为最新缓存),而不是单独请求某个特定修改过的资源文件,因为manifest是不知道哪个文件被修改过了的。
对于全局更新不必要担心,因为没有更新过的资源文件,请求依旧是304响应,只有真正更新过的资源文件才是服务器返回的才是200.
所以控制离线存储的更新,需要2个步骤,一是更新资源文件,二是更新manifest文件,只要修改manifest文件随意一处,浏览器就会感知manifest文件更新,而我们的资源文件名称通常是固定的,需要更新manifest文件怎么操作呢?一个比较好的方式是更新以# 开头的版本号注释,告诉浏览器这个manifest文件被更新过。
manifest资源是滞后静默更新的

第二次刷新界面之后,才能看到更新后的效果

/*code1,简单粗暴的*/
applicationCache.onupdateready = function(){
applicationCache.swapCache(); //强制替换缓存
location.reload(); //重新加载页面
};
/*code2,缓存公用方法*/
// var EventUtil = {
// addHandler: function(element, type, handler) {
// if (element.addEventListener) {
// element.addEventListener(type, handler, false);
// } else if (element.attachEvent) {
// element.attachEvent("on" + type, handler);
// } else {
// element["on" + type] = handler;
// }
// }
// };
// EventUtil.addHandler(applicationCache, "updateready", function() { //缓存更新并已下载,要在下次进入页面生效
// applicationCache.update(); //检查缓存manifest文件是否更新,ps:页面加载默认检查一次。
// applicationCache.swapCache(); //交换到新的缓存项中,交换了要下次进入页面才生效
// location.reload(); //重新载入页面
// });applicationCache 提供了如下的事件:
Event handler Event handler event type
onchecking checking
onerror error
onnoupdate noupdate
ondownloading downloading
onprogress progress
onupdateready updateready
oncached cached
onobsolete obsolete
提供了如下的API:
void update();
// 更新, 但是这个方法适用于一些长期打开的页面,而不会有刷新动作,比如邮件系统,所以这个就比较适合做自动更新下载
void abort();
// 取消
void swapCache();
// 替换缓存内容 ,对于manifest文件的改变,通常是下一次的刷新才会触发下载更新,第二次刷新才会切换使用新的缓存文件,通过这个方法,可以强制将缓存替换
注意事项
站点中的其他页面即使没有设置manifest属性,请求的资源如果在缓存中也从缓存中访问
系统会自动缓存引用清单文件的 HTML 文件
如果manifest文件,或者内部列举的某一个文件不能正常下载,整个更新过程将视为失败,浏览器继续全部使用老的缓存
在manifest中使用的相对路径,相对参照物为manifest文件
站点离线存储的容量限制是5M
manifest文件中CACHE则与NETWORK,FALLBACK的位置顺序没有关系,如果是隐式声明需要在最前面
manifest中必须一一声明文件名,这很令人头痛
引用manifest的html必须与manifest文件同源,在同一个域下
除此之外,还增加了两大问题:
(1)PV UV的计算难题,由于当前页面被强制加入manifest,那么PV 和UV的统计,成了一个难题,因为请求不再是发送到服务器;
(2)缓存对于某个使用manifest的文件,其带有的参数可能是随机性的统计参数,如sid=123sss, sid=234fff ,尤其是比如商品详情的id字段等,这样每个页面都自动加入到manifest中,将会带来很大的存储开销,而且是毫无意义的;
所以伴随而来的,是如何在现有的体系架构下进行数据统计的难题,
对于第一个问题 常规方案是进入离线存储页面后自动发出ajax请求,以告知服务器统计PV UV;
对于第二个问题,是将GET请求方式改成POST方式。
离线存储的适用场景
1.单页应用
2.对实时性要求不高的业务
3.webApp
参考链接
- [1]http://www.zhangxinxu.com/wordpress/2013/05/caching-tutorial-for-web-authors-and-webmasters/
- [2]http://www.codeceo.com/article/http-cache-control.html
- [3]http://www.cnblogs.com/Joans/p/3956490.html
- [4]http://web.jobbole.com/86970/
- [5]http://www.jianshu.com/p/1a9268594deb
- [6]http://blog.techbeta.me/2016/02/http-cache/
- [7]http://hahack.com/wiki/sundries-http-web.html
- [8]http://www.jianshu.com/p/99dc1f8f62bf