0x1 前言
在先知偶然看到了一篇文章zzzphp V1.6.1 远程代码执行漏洞分析,关于模版getshell其实很普遍,这种漏洞分析的乐趣在于跟踪恶意代码的全过程,很可惜先知上的作者可能对这方面不是很感兴趣,直接丢出了payload,正好自己最近很想看下一些cms具体是如何解析模版的,比如之前那个seacms,很值得我去学习。
0x2 漏洞利用回溯分析
漏洞URL:http://127.0.0.1:8888/zzzphp/search
入口是:index.php->zzzclient.php
/Users/xq17/www/zzzphp/inc/zzz_client.php
require 'zzz_template.php';
if (conf('webmode')==0) error(conf('closeinfo'));
$location=getlocation();
ParseGlobal(G('sid'),G('cid'));
//echop($location);die;
switch ($location) { //$location=search
case 'about':
$tplfile= TPL_DIR . G('stpl');
break;
case 'brand':
$stpl=splits(db_select('brand','b_template',"bid=".G('bid') or "b_name='".G('bname')."'"),',');
if (defined('ISWAP')){
$tplfile=isset($stpl[1]) ? $stpl[1] : $stpl[0];
}else{
$tplfile=$stpl[0];
}
$tplfile=empty($tplfile) ? TPL_DIR .'brand.html' : TPL_DIR . $tplfile ;
break;
case 'brandlist':
$tplfile=isset($stpl) ? TPL_DIR . $stpl: TPL_DIR . 'brandlist.html';
$GLOBALS['tid']='-1';
break;
case 'content':
$tplfile= TPL_DIR . G('ctpl');
break;
case 'list':
$tplfile= TPL_DIR . G('stpl');
break;
case 'taglist':
$tplfile=TPL_DIR . 'taglist.html';
$GLOBALS['tid']='-1';
break;
case 'user':
$tplfile= TPL_DIR . 'user.html';
break;
case 'search':
$tplfile= TPL_DIR . 'search.html'; //从这步开始
break;先记着$tplfile=/Users/xq17/www/zzzphp/template/pc/cn2016/html/search.html $location=search
然后继续跟踪$tplfile 继续读下去
就会发现在137~140 行进行了解析模版操作
$zcontent = load_file($tplfile,$location);
$parser = new ParserTemplate(); //2l行 require 'zzz_template.php';
$zcontent = $parser->parserCommom($zcontent); // 解析模板
echo $zcontent;跟进load_file函数了解下作用
zzz_file.php
function load_file( $path, $location = NULL ) {
$path = str_replace( '//', '/', $path );//规范路径
if ( is_file( $path ) ) { //判断是不是文件
return file_get_contents( $path ); //直接返回内容
} elseif ( !is_null( $location ) ) {
$locationpath = PLUG_DIR . 'template/' . $location . '.tpl';
if ( is_file( $locationpath ) ) {
return file_get_contents( $locationpath );
} else {
$url = $_SERVER[ 'REQUEST_URI' ];
$url = sub_left( $url, '?' );
phpgo( $url );
return false;
}
} elseif ( is_file( SITE_DIR . $path ) ) {
return file_get_contents( SITE_DIR . $path );
} else {
error( "载入文件失败,请检查文件路径!," . str_replace( DOC_PATH, '', $path ) );
return false;
}
}所以函数作用是: 获取文件或者模版的内容
这个时候$zcontent的内容就是/Users/xq17/www/zzzphp/template/pc/cn2016/html/search.html
我们可以看下:
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>关键词【{zzz:keys}】搜索结果-{zzz:sitetitle}</title>
<meta name="Keywords" content="{zzz:pagekeys}" >
<meta name="Description" content="{zzz:pagedesc}">
<meta name="author" content="http://www.zzzcms.com" />
<script src="{zzz:tempath}js/jquery-1.8.3.min.js" type="text/javascript"></script>
<link rel="stylesheet" type="text/css" href="{zzz:tempath}css/styles.css" />
<script src="{zzz:tempath}js/img.js" type="text/javascript"></script>
</head>
<body>
<!--head--> {zzz:top}
<div class="s_banner2"></div>
<div class="path_box">
<div class="path_con">
<div class="pc_title"><img src="{zzz:tempath}images/2_08.png" /><span>站内搜索</span><i>search</i></div>
<div class="sub_title">关键词:{zzz:pagekeys}</div>
<div class="pc_text"> 位置{zzz:location}</div>
<div class="clear"></div>
</div>
</div>
<div class="contact_box">
<div class="contact_inf">
<div class="sub_list">
<dl>
{zzz:navlist sid=5,6}
<dd {if:[navlist:sid]= {zzz:sid}}class="sub_on"{end if}> <a href="[navlist:link]">[navlist:name]</a></dd>
{/zzz:navlist}
</dl>
</div>
<div class="sub_right">
<div class="news">
<div class="news_list"> {zzz:search size=5 order=order}
<dl>
<dt>[search:date]</dt>
<dd><a href="[search:link]" title="[search:title]">[search:title]</a></dd>
<div class="clear"></div>
</dl>
{/zzz:search} </div>
{list:page len=3 style=1} </div>
</div>
<div class="clear"></div>
</div>
</div>
<!--foot--> {zzz:foot}
</body>
</html>里面包含了cms定义的各种标签。
接下来就是我想重点分析的部分了
0x3 解析模版过程
从上面然后执行到了这一句:$zcontent = $parser->parserCommom($zcontent);
跟进代码:
/Users/xq17/www/zzzphp/inc/zzz_template.php
function parserCommom( $zcontent ) {
$zcontent = $this->parserSiteLabel( $zcontent ); // 站点标签
$zcontent = $this->ParseInTemplate( $zcontent ); // 模板标签
$zcontent = $this->parserConfigLabel( $zcontent ); //配置表情
$zcontent = $this->parserSiteLabel( $zcontent ); // 站点标签
$zcontent = $this->parserCompanyLabel( $zcontent ); // 公司标签
$zcontent = $this->parserlocation( $zcontent ); // 站点标签
$zcontent = $this->parserLoopLabel( $zcontent ); // 循环标签
$zcontent = $this->parserContentLoop( $zcontent ); // 指定内容
$zcontent = $this->parserbrandloop( $zcontent );
$zcontent = $this->parserGbookList( $zcontent );
$zcontent = $this->parserUser( $zcontent ); //会员信息
$zcontent = $this->parserLabel( $zcontent ); // 指定内容
$zcontent = $this->parserPicsLoop( $zcontent ); // 内容多图
$zcontent = $this->parserad( $zcontent );
$zcontent = parserPlugLoop( $zcontent );
$zcontent = $this->parserOtherLabel( $zcontent );
$zcontent = $this->parserIfLabel( $zcontent ); // IF语句
$zcontent = $this->parserNoLabel( $zcontent );
return $zcontent;
}可以很清楚看到写了不同的函数去解析对应的标签,这里我们不妨直接跟进第一个来了解代码流程。
$zcontent = $this->parserSiteLabel( $zcontent );
function parserSiteLabel( $zcontent ) {
$pattern = '/{zzz:([w]+)?}/';
if ( preg_match_all( $pattern, $zcontent, $matches ) ) {
$count = count( $matches[ 0 ] );//看下有多少个成功匹配的 二维数组的总长度
for ( $i = 0; $i < $count; $i++ ) {
switch ( $matches[ 1 ][ $i ] ) { //结果
case 'qqkf1':
$zcontent = str_replace( $matches[ 0 ][ $i ], load_file( SITE_DIR . "plugins/qqkf/qqkf1.html" ), $zcontent );
break;
case 'qqkf2':
$zcontent = str_replace( $matches[ 0 ][ $i ], load_file( SITE_DIR . "plugins/qqkf/qqkf2.html" ), $zcontent );
break;
case 'qqkf3':
$zcontent = str_replace( $matches[ 0 ][ $i ], load_file( SITE_DIR . "plugins/qqkf/qqkf3.html" ), $zcontent );
break;
case 'wapkf':
$zcontent = str_replace( $matches[ 0 ][ $i ], load_file( SITE_DIR . "plugins/qqkf/wapkf.html" ), $zcontent );
break;
case 'baidumap':
$zcontent = str_replace( $matches[ 0 ][ $i ], load_file( SITE_DIR . 'plugins/baidumap.html' ), $zcontent );
break;
case 'sitepath':
$zcontent = str_replace( $matches[ 0 ][ $i ], SITE_PATH, $zcontent );
break;
case 'wappath':
$zcontent = str_replace( $matches[ 0 ][ $i ], SITE_PATH.'wap/', $zcontent );
break;
case 'plugpath':
$zcontent = str_replace( $matches[ 0 ][ $i ], SITE_PATH . 'plugins/', $zcontent );
break;
case 'version':
$zcontent = str_replace( $matches[ 0 ][ $i ], VERSION, $zcontent );
break;
case 'tempath':
$zcontent = str_replace( $matches[ 0 ][ $i ], TPL_PATH, $zcontent );
break;
case 'nowtime':
case 'time':
$zcontent = str_replace( $matches[ 0 ][ $i ], date( 'Y-m-d H:i:s' ), $zcontent );
break;
case 'Y': case 'm': case 'd': case 'H': case 'i': case 's':
$zcontent = str_replace( $matches[ 0 ][ $i ], date( ''.$matches[ 1 ][ $i ].'' ), $zcontent );
break;
case 'sitename':
$zcontent = str_replace( $matches[ 0 ][ $i ], '{zzz:sitetitle}', $zcontent );
break;
case 'sitetitle2':
$zcontent = str_replace( $matches[ 0 ][ $i ], '{zzz:additiontitle}', $zcontent );
break;
case 'logo':
case 'pclogo':
$zcontent = str_replace( $matches[ 0 ][ $i ], '{zzz:sitepclogo}', $zcontent );
break;
case 'waplogo':
$zcontent = str_replace( $matches[ 0 ][ $i ], '{zzz:sitewaplogo}', $zcontent );
break;
case 'company':
$zcontent = str_replace( $matches[ 0 ][ $i ], '{zzz:companyname}', $zcontent );
break;
case 'address':
$zcontent = str_replace( $matches[ 0 ][ $i ], '{zzz:companyaddress}', $zcontent );
break;
case 'postcode':
$zcontent = str_replace( $matches[ 0 ][ $i ], '{zzz:companypostcode}', $zcontent );
break;
case 'contact':
$zcontent = str_replace( $matches[ 0 ][ $i ], '{zzz:companycontact}', $zcontent );
break;
case 'tel':
$zcontent = str_replace( $matches[ 0 ][ $i ], '{zzz:companytel}', $zcontent );
break;
case 'mobile':
$zcontent = str_replace( $matches[ 0 ][ $i ], '{zzz:companymobile}', $zcontent );
break;
case 'fax':
$zcontent = str_replace( $matches[ 0 ][ $i ], '{zzz:companyfax}', $zcontent );
break;
case 'siteicp':
$zcontent = str_replace( $matches[ 0 ][ $i ], '{zzz:companyicp}', $zcontent );
break;
case 'desc':
case 'sitedesc':
case 'pagedesc':
$zcontent = str_replace( $matches[ 0 ][ $i ], '{zzz:sitedesc}', $zcontent );
break;
case 'top':
case 'head':
$zcontent = str_replace( $matches[ 0 ][ $i ], '{zzz:template src=head.html}', $zcontent );
break;
case 'foot':
case 'end':
$zcontent = str_replace( $matches[ 0 ][ $i ], '{zzz:template src=foot.html}', $zcontent );
break;
case 'left':
$zcontent = str_replace( $matches[ 0 ][ $i ], '{zzz:template src=left.html}', $zcontent );
break;
case 'right':
$zcontent = str_replace( $matches[ 0 ][ $i ], '{zzz:template src=right.html}', $zcontent );
break;
case 'userlogin':
$zcontent = str_replace( $matches[ 0 ][ $i ], "<script language='javascript' src='" . PLUG_PATH . "template/login.php?backurl=".G( 'backurl' )."''></script>", $zcontent );
break;
case 'gbookform':
$zcontent = str_replace( $matches[ 0 ][ $i ], "<iframe width='100%' height='100%' frameborder='0' style='min-height:500px;' src='" . PLUG_PATH . "template/gbook.php'></iframe>", $zcontent );
break;
}
}
}
return $zcontent;
}$pattern = '/{zzz:([w]+)?}/'; 这个正则其实就是匹配{zzz:(匹配内容)}这样的格式

这里就从{zzz:keys} 为例子,没有,直接返回了内容(这里是解析站点标签的,可能在其他函数会处理keys)
这里比如
case 'version':
$zcontent = str_replace( $matches[ 0 ][ $i ], VERSION, $zcontent ); //进行了个替换操作
break;0x4 重点分析漏洞形成点
在众多解析标签的函数中,$zcontent = $this->parserIfLabel( $zcontent ); // IF语句
我们选择跟进解析if语句的函数。
function parserIfLabel( $zcontent ) {
$pattern = '/{if:([sS]+?)}([sS]*?){ends+if}/';
if ( preg_match_all( $pattern, $zcontent, $matches ) ) {
$count = count( $matches[ 0 ] );
for ( $i = 0; $i < $count; $i++ ) {
$flag = '';
$out_html = '';
$ifstr = $matches[ 1 ][ $i ];
$ifstr = str_replace( '<>', '!=', $ifstr );
$ifstr = str_replace( 'mod', '%', $ifstr );
$ifstr1 = cleft( $ifstr, 0, 1 );
switch ( $ifstr1 ) {
case '=':
$ifstr = '0' . $ifstr;
break;
case '{':
case '[':
$ifstr = "'" . str_replace( "=", "'=", $ifstr );
break;
}
$ifstr = str_replace( '=', '==', $ifstr );
$ifstr = str_replace( '===', '==', $ifstr );
@eval( 'if(' . $ifstr . '){$flag="if";}else{$flag="else";}' );
if ( preg_match( '/([sS]*)?{else}([sS]*)?/', $matches[ 2 ][ $i ], $matches2 ) ) { // 判断是否存在else
switch ( $flag ) {
case 'if': // 条件为真
if ( isset( $matches2[ 1 ] ) ) {
$out_html .= $matches2[ 1 ];
}
break;
case 'else': // 条件为假
if ( isset( $matches2[ 2 ] ) ) {
$out_html .= $matches2[ 2 ];
}
break;
}
} elseif ( $flag == 'if' ) {
$out_html .= $matches[ 2 ][ $i ];
}
// 无限极嵌套解析
$pattern2 = '/{if([0-9]):/';
if ( preg_match( $pattern2, $out_html, $matches3 ) ) {
$out_html = str_replace( '{if' . $matches3[ 1 ], '{if', $out_html );
$out_html = str_replace( '{else' . $matches3[ 1 ] . '}', '{else}', $out_html );
$out_html = str_replace( '{end if' . $matches3[ 1 ] . '}', '{end if}', $out_html );
$out_html = $this->parserIfLabel( $out_html );
}
// 执行替换
$zcontent = str_replace( $matches[ 0 ][ $i ], $out_html, $zcontent );
}
}
return $zcontent;
}里面有句@eval( 'if(' . $ifstr . '){$flag="if";}else{$flag="else";}' );直接eval了变量,那么我们从头开始分析,eval里面的内容是否可控。
$pattern = '/{if:([sS]+?)}([sS]*?){ends+if}/';
分析下这个正则是怎么匹配的
(括号代表的是匹配的组)
sS 是任意匹配内容(比.还要强可以匹配换行等等)
ends+if 代表 end 和 if之间至少要有个空白符(空白 换行等)
也就是说这个正则匹配的格式:
{if:(匹配内容)}(匹配内容){end if}
继续分析下他的代码。
提取重要部分出来如下:
$flag = '';
$out_html = '';
$ifstr = $matches[ 1 ][ $i ]; //匹配的内容 {if:phpinfo()};{end if}->$ifstr=phpinfo()
$ifstr = str_replace( '<>', '!=', $ifstr );//<>替换为!=
$ifstr = str_replace( 'mod', '%', $ifstr ); //mod 替换为%
$ifstr1 = cleft( $ifstr, 0, 1 );//提取第一个值 p
//function cleft( $str, $start = 0, $num = 1 ) {
//$var = trim( $str );
//$result = substr( $var, $start, $num );
//return $result;
switch ( $ifstr1 ) { //这个选择结构可以直接跳过了
case '=':
$ifstr = '0' . $ifstr;
break;
case '{':
case '[':
$ifstr = "'" . str_replace( "=", "'=", $ifstr );
break;
}
$ifstr = str_replace( '=', '==', $ifstr ); //= 替换为==
$ifstr = str_replace( '===', '==', $ifstr ); // ===替换为==
@eval( 'if(' . $ifstr . '){$flag="if";}else{$flag="else";}' );
//最后拼接结果就是 if(phpinfo()){$flag="if";}else{$flag="else";}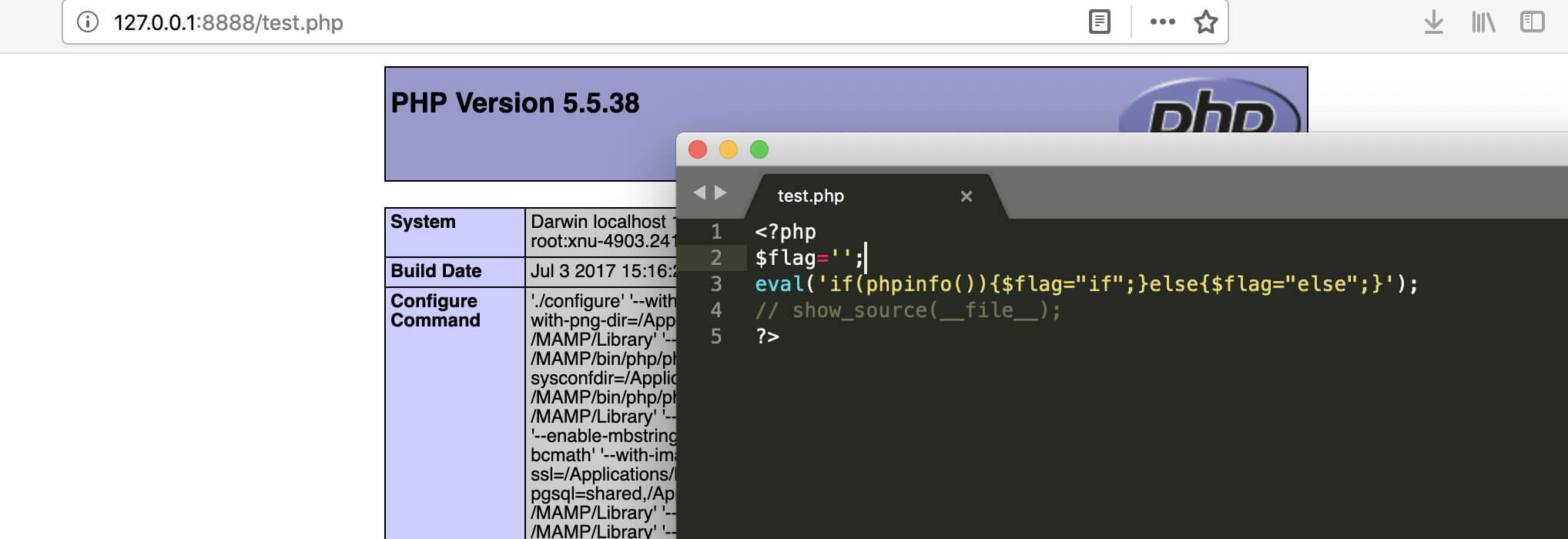
0x5 关于漏洞利用
先知那片文章的payload已经给的很详细了,根据我的分析你也能很简单写出来了。
直接加入个if格式的标签就可以直接rce了。
0x6 总结
虽然这个漏洞简单,但是换做我以前的话估计就是粗略扫一下,大概明白漏洞思路,而不会去仔细分析,从而丢失了学习机会,但是现在我觉得自己对待学习代码审计的过程中,认真严谨的学习模式才能让自己有所提高。
- 本文由安全客原创发布
- 转载,请参考转载声明,注明出处: https://www.anquanke.com/post/id/173991
- 安全客 - 有思想的安全新媒体